
Three Paradigms of Retrieval-Augmented Generation (RAG) for LLMs
Retrieval-Augmented Generation (RAG) has emerged as a promising technique to enhance the capabilities of large language models by incorporating external knowledge sources. As research in this area has progressed, three distinct paradigms of RAG have emerged: Naive RAG, Advanced RAG, and Modular RAG.

Reference Paper: Retrieval-Augmented Generation for Large Language Models: A Survey https://arxiv.org/pdf/2312.10997
Naive RAG
This represents the earliest and most basic RAG methodology. It follows a traditional process of indexing documents into a vector database, retrieving the top relevant chunks based on similarity to the user's query, and then inputting the query along with the retrieved chunks into a language model to generate the final answer.
For example, if the user asks "What is the capital of France?", Naive RAG would:
Index documents/passages containing information about countries and capitals
Retrieve the top chunks most semantically similar to the query
Input the query "What is the capital of France?" along with the retrieved chunks to a language model
The language model generates the answer "The capital of France is Paris" based on the provided context
While cost-effective, Naive RAG has some key limitations, The development of Advanced RAG and Modular RAG is a response to these specific shortcomings in Naive RAG.
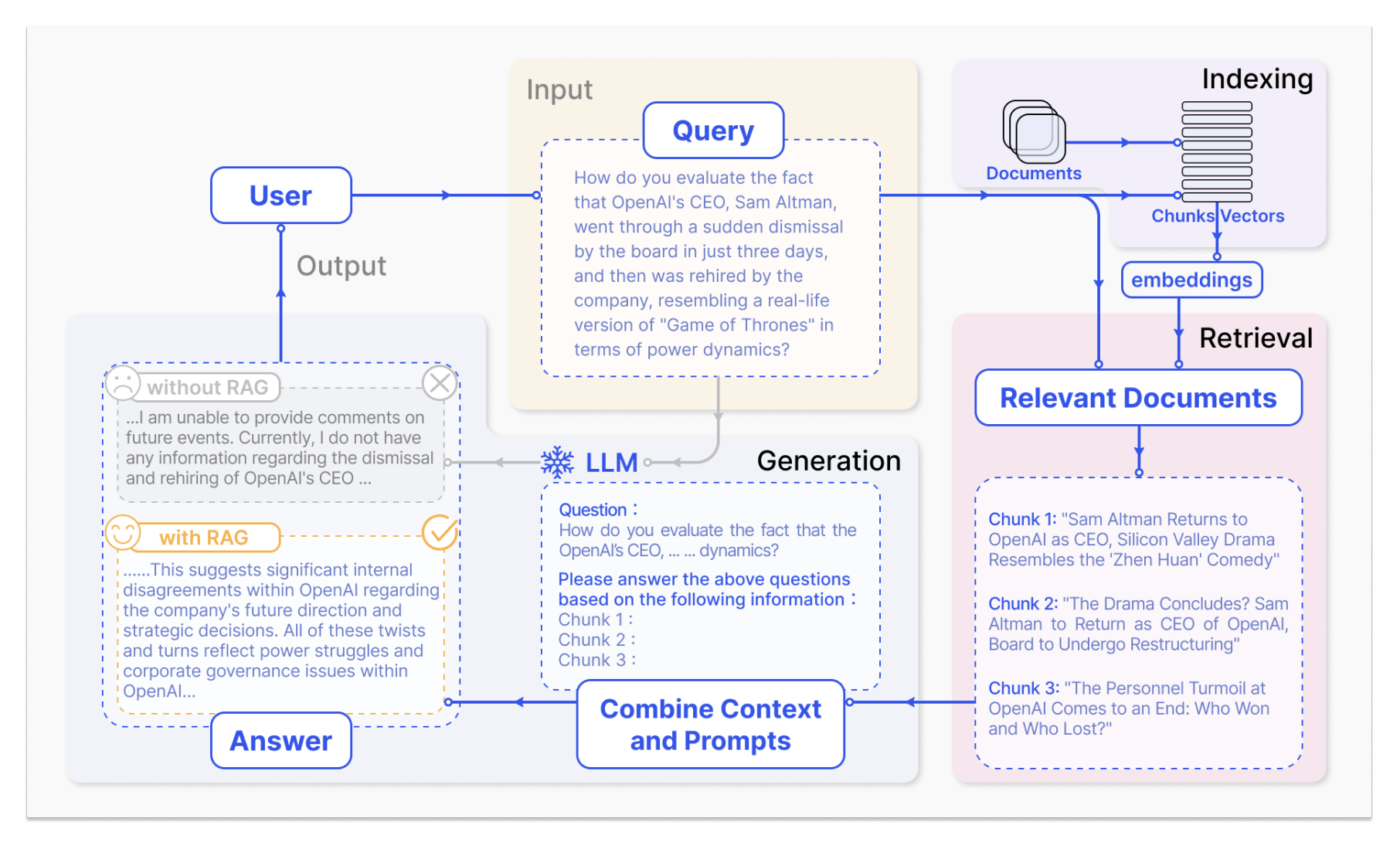
RAG process applied to question answering, consists of 3 steps.
Indexing: Documents are split into chunks, encoded into vectors, and stored in a vector database.
Retrieval: Retrieve the Top k chunks most relevant to the question based on semantic similarity.
Generation: Input the original question and the retrieved chunks together into LLM to generate the final answer.
Reference Paper: Retrieval-Augmented Generation for Large Language Models: A Survey https://arxiv.org/pdf/2312.10997
Advanced RAG
To overcome the shortcomings of Naive RAG, the Advanced RAG paradigm introduces optimization strategies around pre-retrieval and post-retrieval processes:
Pre-Retrieval:
Optimizing indexing (rewriting, expansion, transformation): Involves enhancing the data granularity by indexing documents at multiple levels like paragraphs and sentences; incorporating metadata such as timestamps, authors, and categories from the original documents; aligning the indexed content through techniques like building hierarchical index structures or knowledge graph indexes to maintain contextual consistency; and employing mixed retrieval approaches that combine sparse retrieval models like BM25 with dense semantic retrievers based on embeddings from language models.
Query optimization (rewriting, expansion, transformation): Aims to refine and enrich the user's original query by employing techniques like query rewriting, where the query is rephrased or rewritten by the language model itself to be more suitable for retrieval; query expansion, where the single query is expanded into multiple related queries to provide additional context; and query transformation, where the query is modified by generating hypothetical documents or step-back prompts to reduce semantic gaps with potential answer contexts during the retrieval process.
Example: Rewriting the query "What's the French capital?" to "What is the capital city of France?"
Post-Retrieval:
Re-ranking retrieved chunks: After the initial retrieval of relevant document chunks based on similarity to the query, re-ranking involves reordering or rescoring these retrieved chunks using rule-based methods like favoring diversity or relevance metrics, or employing specialized model-based re-rankers like SpanBERT or large language models themselves, with the goal of prioritizing and positioning the most pertinent chunks towards the beginning of the context provided to the language model for generating the final answer.
Example: Putting the most relevant sentence "Paris is the capital of France" at the start
Context compression and selection: Even after re-ranking the retrieved chunks, providing the entire concatenated context to the language model can introduce noise and make it challenging for the model to identify the most salient information required to generate an accurate answer. Context compression and selection techniques aim to address this issue by condensing and distilling only the essential segments from the retrieved context. This can involve training specialized models using contrastive learning to detect and remove superfluous or less relevant content. For instance, if the original retrieved context contains multiple sentences, the compression model may identify and remove less relevant sentences, shortening the context to only the most pertinent pieces of information. This focused, compressed context can then be provided as input to the language model, enabling it to better concentrate on the critical knowledge required while avoiding distractions from tangential or redundant content.
Example: Removing less relevant sentences to shorten the context
By refining both the input query and handling of retrieved content, Advanced RAG aims to improve the quality and relevance of information provided to language models.
Modular RAG
Building upon Advanced RAG, Modular RAG offers even greater flexibility and adaptability through specialized modules and reconfigurable pipelines:
New Modules:
Search module for accessing diverse data sources: The search module enables the RAG system to directly query and retrieve information from a variety of data sources beyond just text corpora, such as search engines, databases, knowledge graphs, and web pages.
Example: Searching Wikipedia, web pages, and databases to gather relevant information
Memory module for iterative self-enhancement: Leverages the LLM’s memory to guide retrieval, creating an unbounded memory pool that aligns the text more closely with data distribution through iterative self-enhancement
Example: Allowing the model to refer to its own previous outputs to enhance future retrievals
Routing module for intelligent navigation: navigates through diverse data sources, selecting the optimal pathway for a query, whether it involves summarization, specific database searches, or merging different information streams
Example: Dynamically routing the query to different retrievers based on topic
Predict module to generate relevant context directly: aims to reduce redundancy and noise by generating context directly through the LLM, ensuring relevance and accuracy
Example: Having the language model generate hypothetical context when no good matches are retrieved
New Patterns:
Techniques like Rewrite-Retrieve-Read, Generate-Read, hybrid retrieval: refine retrieval queries through a rewriting module and a LM-feedback mechanism to update rewriting model, improving task performance. Similarly, Generate-Read replaces traditional retrieval with LLM-generated content, while ReciteRead emphasizes retrieval from model weights, enhancing the model’s ability to handle knowledge-intensive tasks.
Example: Rewriting the original query, retrieving, reading retrieved context, generating an answer
Dynamic pipelines like Demonstrate-Search-Predict: Dynamic use of module outputs to bolster another module’s functionality, illustrating a sophisticated understanding of enhancing module synergy.
Example: Demonstrating steps to solve a problem, searching for relevant info, predicting the final answer
Flexible and adaptive retrieval flows: This approach transcends the fixed RAG retrieval process by evaluating the necessity of retrieval based on different scenarios.
Example: Deciding whether to retrieve again or generate the final answer based on current context quality
Easier integration with fine-tuning and other methods: Another benefit of a flexible architecture is that the RAG system can more easily integrate with other technologies (such as fine-tuning or reinforcement learning)
Example: Fine-tuning the retrieval and generation components on specific datasets
The key advantage of Modular RAG is its ability to substitute or rearrange modules to address specific challenges across different tasks and scenarios effectively.
Conclusion

RAG Ecosystem
Reference Paper: Retrieval-Augmented Generation for Large Language Models: A Survey https://arxiv.org/pdf/2312.10997
As RAG techniques evolve from Naive to Advanced to Modular paradigms, they offer increasingly powerful and flexible ways to augment large language models with external knowledge sources. This comprehensive survey paper provides a structured understanding of this technological progression within the field of retrieval-augmented natural language processing.