
OWASP Top 10 for LLMs and GenAI Cheatsheet
The OWASP Top 10 for Large Language Models represents the most critical security risks facing AI applications in 2025. As LLMs become increasingly embedded in applications across industries, understanding and mitigating these risks is crucial for developers and security professionals. In this article let’s go over an AI application architecture covering each of the OWASP Top 10 for LLMs and understand the prevention methods for each.
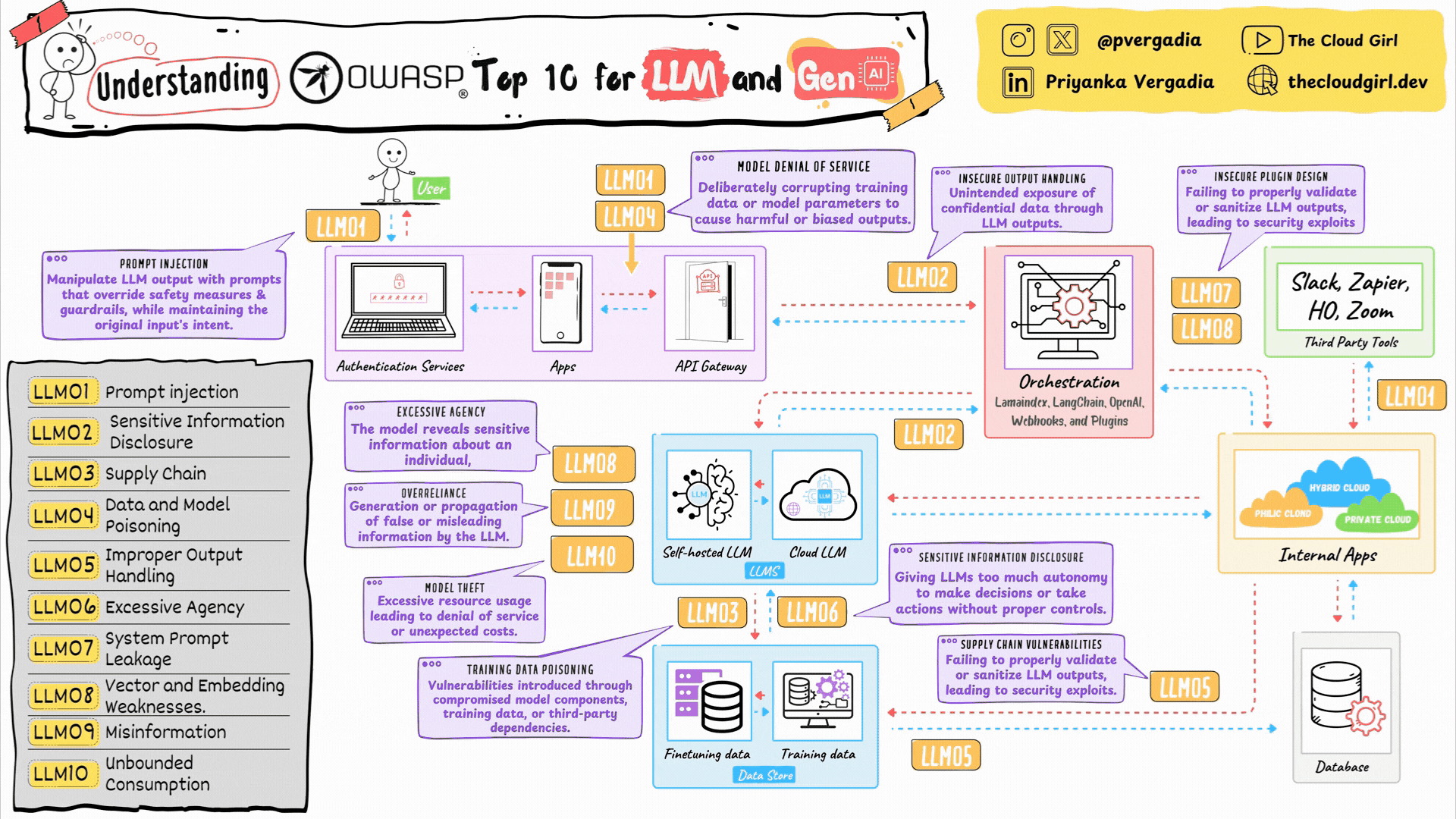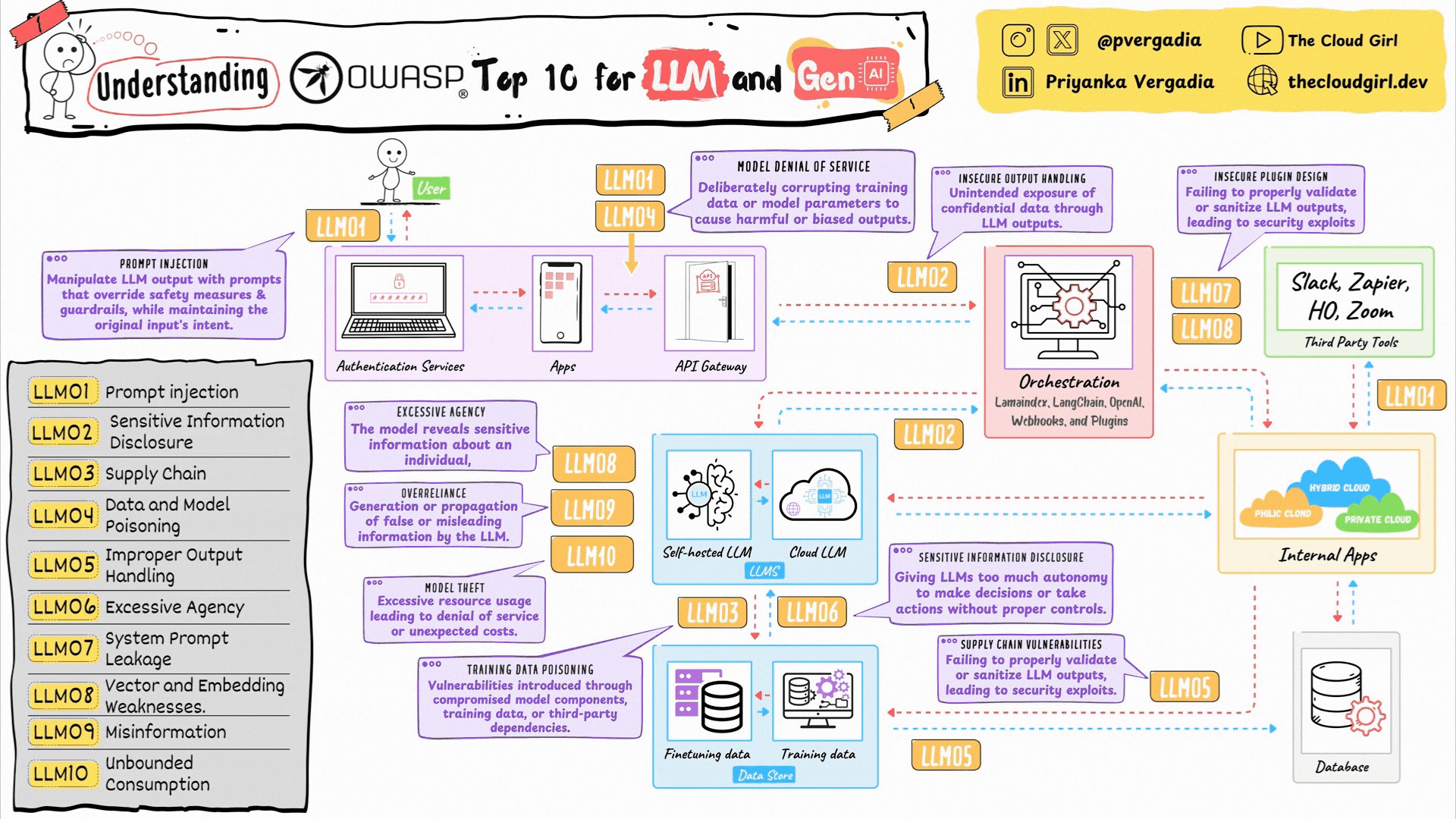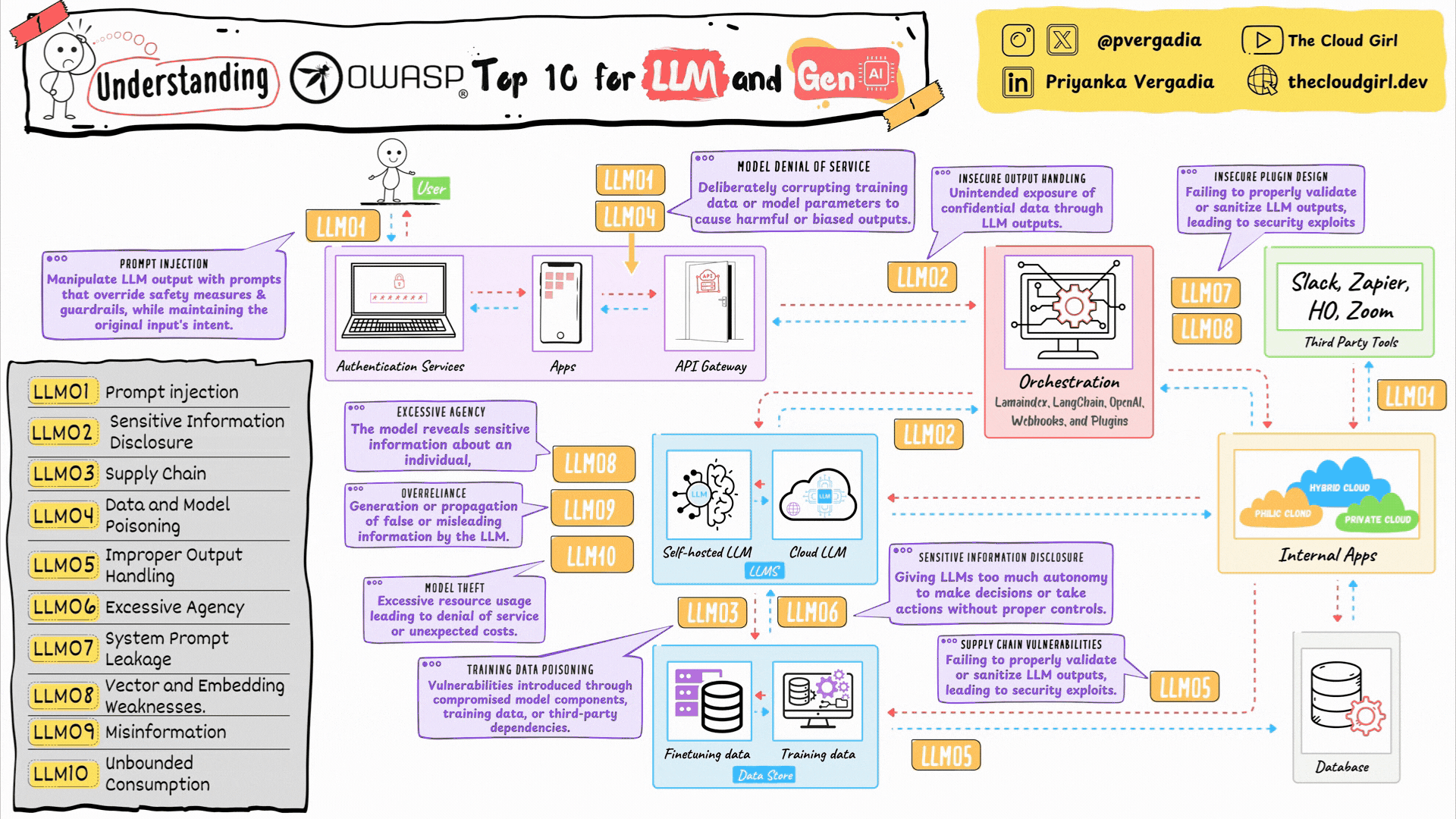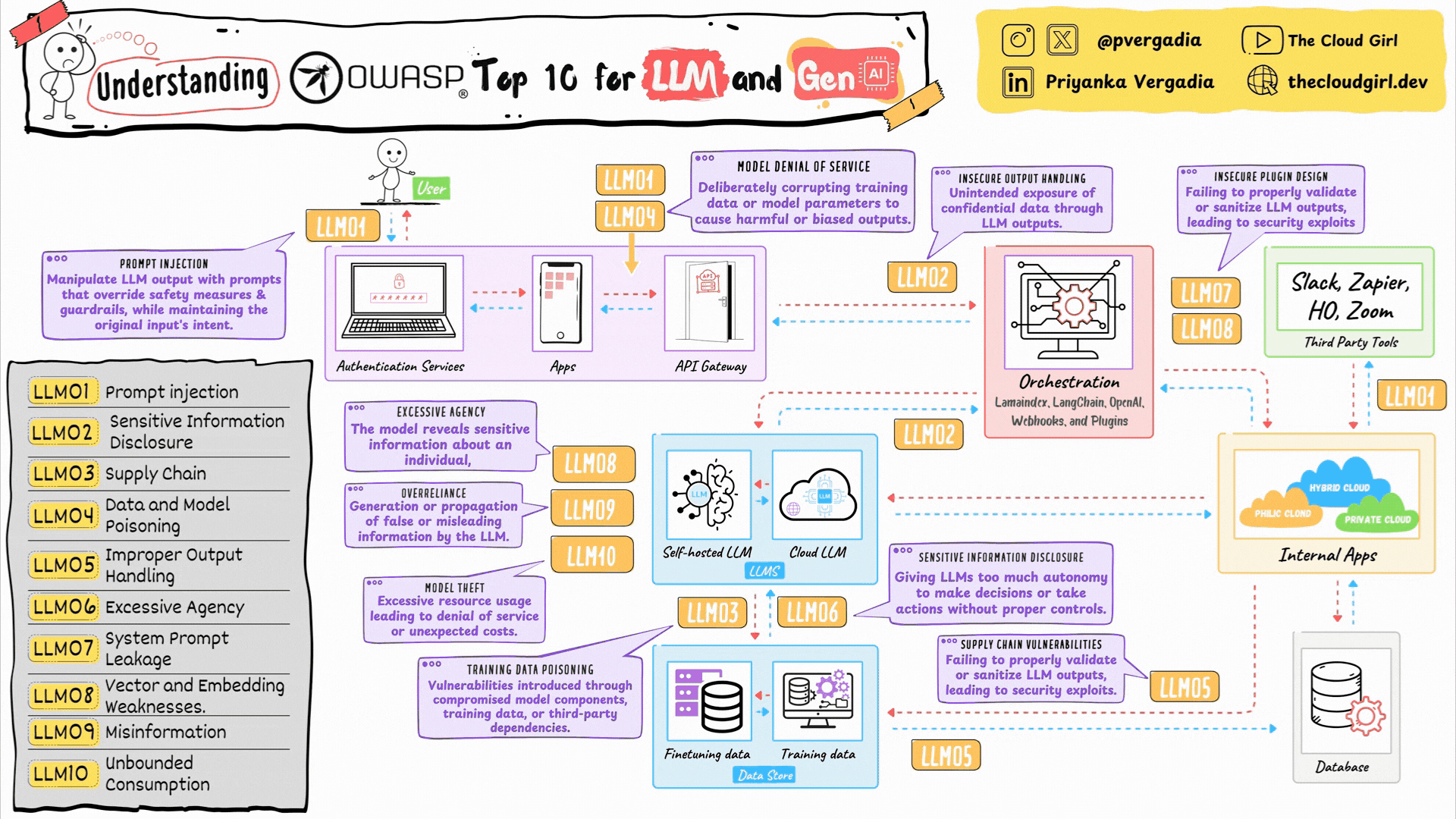
OWASP Top 10 for LLMs and GenAI using an architecture diagram
LLM01. Prompt Injection
Prompt injection occurs when malicious input manipulates an LLM to behave in unintended ways. These attacks can succeed even with imperceptible alterations to inputs and may bypass existing safety controls.
In a notable case, attackers successfully manipulated a customer support chatbot by crafting prompts that made it ignore safety guidelines, leading to the exposure of sensitive customer information. Another significant incident involved job applicants embedding hidden instructions within their resumes, causing AI-based hiring systems to unfairly favor their applications. Security researchers have also demonstrated how specially crafted inputs can make an LLM completely disregard its original purpose, instead executing potentially harmful commands or revealing confidential information.
Prevention:
Implement robust input validation and sanitization
Use strict context enforcement
Deploy multiple layers of prompt security controls
Regular security testing and monitoring
LLM02. Sensitive Information Disclosure
LLMs can inadvertently expose confidential data through their outputs, including PII, financial details, and proprietary information.
Several organizations have reported incidents where their LLM systems inadvertently revealed internal system architecture details through detailed error messages. In one case, an AI-powered code assistant exposed API keys and credentials through its verbose responses to user queries. Another concerning incident involved a document summarization service that accidentally included private user data in its generated reports, leading to potential privacy violations.
Prevention:
Implement data sanitization pipelines
Use strict access controls
Apply differential privacy techniques
Regular auditing of LLM outputs
LLM03. Supply Chain Dependencies
Vulnerabilities in the AI supply chain, from training data to model deployment, can compromise system security.
A major security breach occurred when developers unknowingly used compromised Python libraries in their model development environment, leading to widespread system vulnerabilities. In another incident, researchers discovered malicious model weights being distributed through public repositories, potentially affecting thousands of downstream applications. Organizations have also faced challenges with poisoned training data that subtly altered model behavior, leading to biased or harmful outputs in production systems.
Prevention:
Verify all model sources and dependencies
Implement robust version control
Regular security audits of the supply chain
Use trusted and verified model repositories
LLM04. Data and Model Poisoning
Attackers can manipulate training data or model parameters to introduce vulnerabilities or backdoors. A sophisticated attack involved researchers demonstrating how injecting biased data during the training process could significantly alter model outputs. Security teams have discovered instances where attackers introduced subtle triggers into training data that caused models to produce harmful content under specific conditions. In a particularly concerning case, malicious actors poisoned fine-tuning datasets to create backdoors in commercial AI systems, allowing them to bypass security measures at will.
Prevention:
Validate training data integrity
Implement robust data cleaning pipelines
Regular model behavior monitoring
Adversarial testing during development
LLM05. Improper Output Handling
Insufficient validation of LLM outputs can lead to security vulnerabilities when those outputs are used in downstream systems. Security researchers uncovered multiple instances where unsanitized LLM outputs led to cross-site scripting (XSS) attacks in web applications. In a significant incident, an AI-powered database interface generated SQL queries that contained injection vulnerabilities, potentially exposing sensitive data. Organizations have also reported cases where unvalidated LLM outputs resulted in malicious code execution when integrated with automated deployment systems.
Prevention:
Implement comprehensive output validation
Use context-aware sanitization
Apply proper output encoding
Regular security testing of output handling
LLM06. Excessive Agency
Giving LLMs too much autonomy or access to system capabilities can lead to security breaches. A critical incident occurred when an LLM-powered automation system with unrestricted access to system commands executed unauthorized operations, causing system outages. In another case, an AI system made autonomous financial decisions without proper oversight, resulting in significant losses. Organizations have reported incidents where LLMs with excessive permissions in connected systems accessed and modified sensitive data beyond their intended scope.
Prevention:
Implement strict permission boundaries
Require human approval for critical actions
Use role-based access control
Regular audit of LLM permissions
LLM07. System Prompt Leakage
Exposure of system prompts can reveal sensitive information and enable other attacks. An investigation revealed that a company's LLM inadvertently leaked internal decision-making processes through its responses, giving competitors insights into proprietary workflows. Security researchers demonstrated how system prompts could expose critical security controls, enabling targeted attacks. In another incident, detailed system architecture information was revealed through carefully crafted prompt injection attacks, compromising system security.
Prevention:
Separate sensitive data from prompts
Implement robust prompt security
Regular security audits
Monitor for prompt exposure
LLM08. Vector and Embedding Attacks
Vulnerabilities in how vectors and embeddings are handled can lead to security breaches. A major security breach occurred when attackers gained unauthorized access to an embedding database, extracting sensitive information from vector representations. Multi-tenant AI systems experienced cross-tenant data leakage when embedding spaces were not properly isolated, exposing confidential information across organizational boundaries. Researchers successfully demonstrated embedding inversion attacks that reconstructed sensitive training data from stored embeddings, compromising data privacy.
Prevention:
Implement proper access controls for embeddings
Use secure embedding storage
Regular security audits
Monitor for unauthorized access
LLM09. Misinformation and Hallucination
LLMs can generate false or misleading information that appears credible but is fabricated. A concerning incident involved an LLM generating highly convincing but completely fabricated security credentials that passed initial verification systems. In another case, an AI system created false technical documentation that appeared authentic, leading to implementation errors in critical systems. Organizations have reported cases where LLMs provided incorrect technical advice that introduced serious vulnerabilities when implemented, highlighting the risks of unchecked AI-generated technical guidance.
Prevention:
Implement fact-checking mechanisms
Use retrieval-augmented generation
Regular output validation
Human oversight for critical information
LLM10. Unbounded Resource Consumption
Uncontrolled resource usage by LLMs can lead to denial of service or excessive costs. Several organizations faced significant financial impacts from denial of wallet attacks where attackers exploited pay-per-call API systems through automated, excessive requests. A cloud-based AI service experienced complete system failure when attackers crafted complex queries designed to maximize resource usage. Security teams have documented cases where continuous input flooding attacks overwhelmed LLM systems, leading to service outages and degraded performance for legitimate users.
Prevention:
Implement rate limiting
Set resource quotas
Monitor resource usage
Use efficient scaling strategies
Conclusion
The OWASP Top 10 for LLM Applications provides essential guidance for securing AI systems. As we build enterprise applications we must implement comprehensive security controls across our entire AI infrastructure while staying informed about emerging threats and mitigation strategies.
Remember that this area is evolving rapidly, and new security challenges may emerge. Regular updates to security measures and continuous monitoring are essential for maintaining robust AI systems.