Latest Large Context Model (LCM) Benchmark Explained: L-CiteEval
As language models continue to evolve, one of the most significant challenges has been handling long-form content effectively. In this article, we'll explore how modern Large Context Models (LCMs) are pushing the boundaries of context windows and what this means for developers working with AI applications.
The Evolution of Context Windows
The landscape of context windows in language models has evolved dramatically:
GPT-3.5 (2022): 4K tokens
Claude 2 (2023): 100K tokens
GPT-4 (2024): 128K tokens
Claude 3 (2024): 200K tokens
Gemini Ultra (2024): 1M tokens
Anthropic Claude (experimental): 1M tokens
This exponential growth in context window sizes represents a fundamental shift in how we can interact with AI systems. For perspective, 1M tokens is roughly equivalent to 750,000 words or about 3,000 pages of text.
We’ll explore and understand LCM with the help of a recent research paper (L-CITEEVAL: DO LONG-CONTEXT MODELS TRULY LEVERAGE CONTEXT FOR RESPONDING?), which highlights the importance of large context with benchmark.

What is Long Context Models (LCMs)?

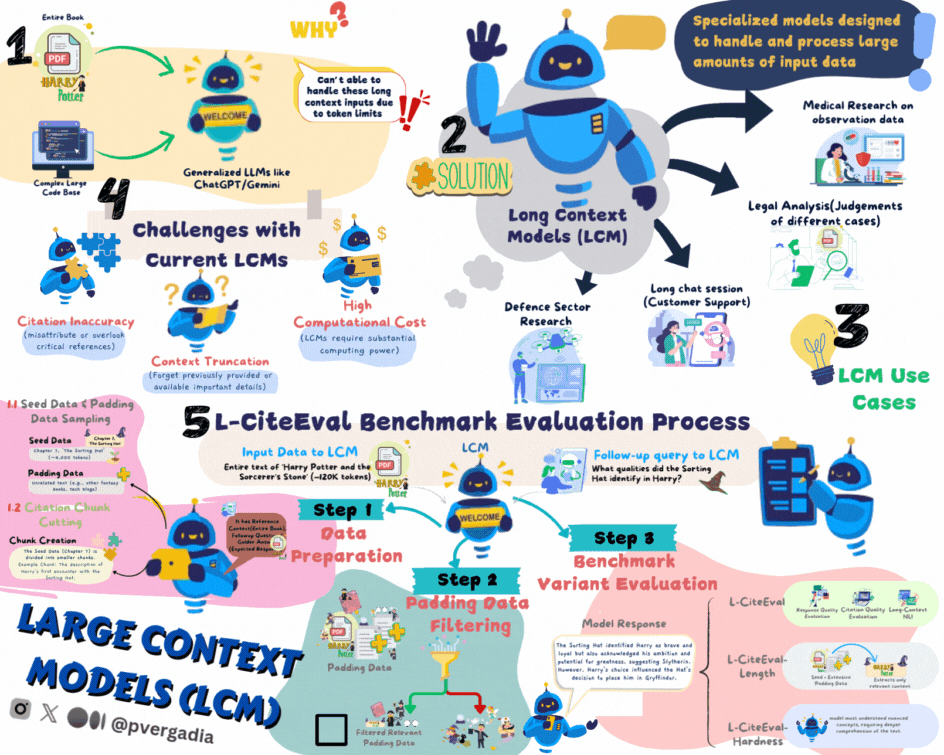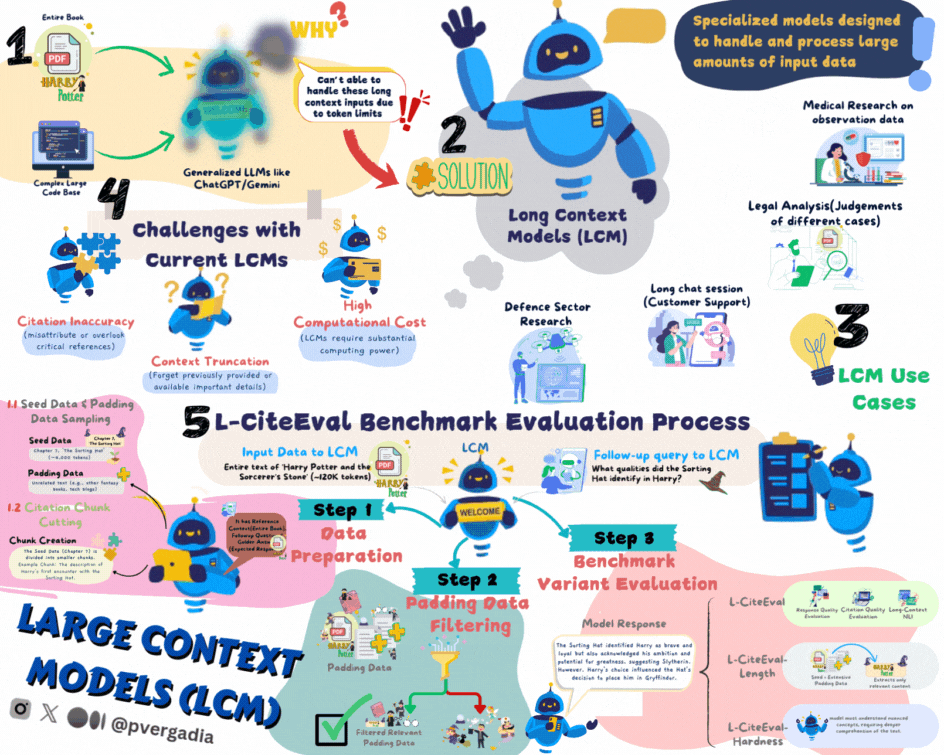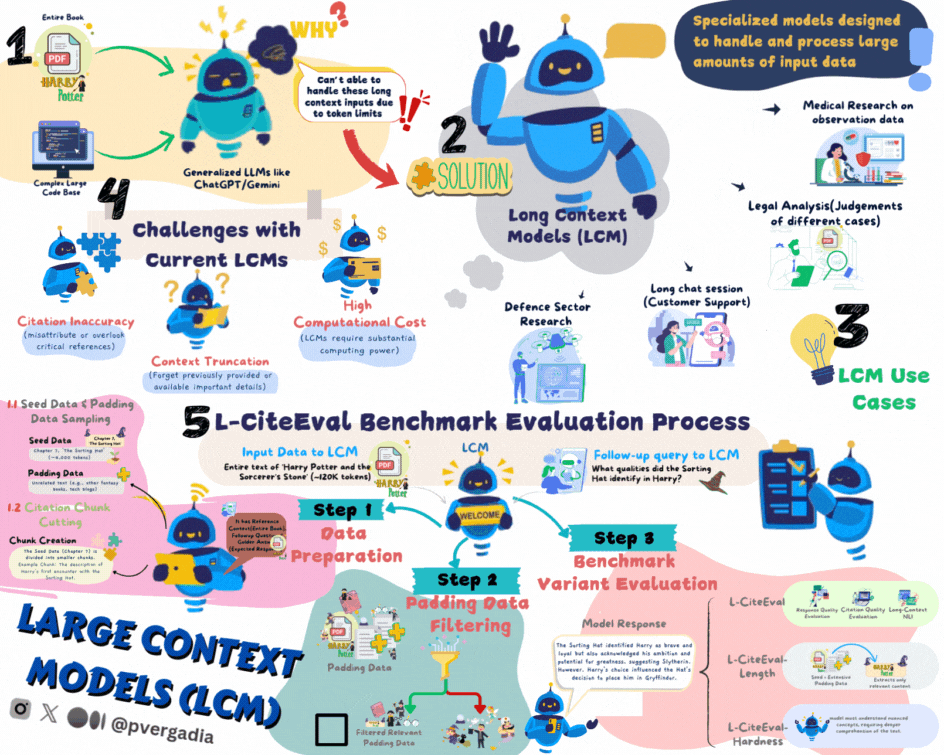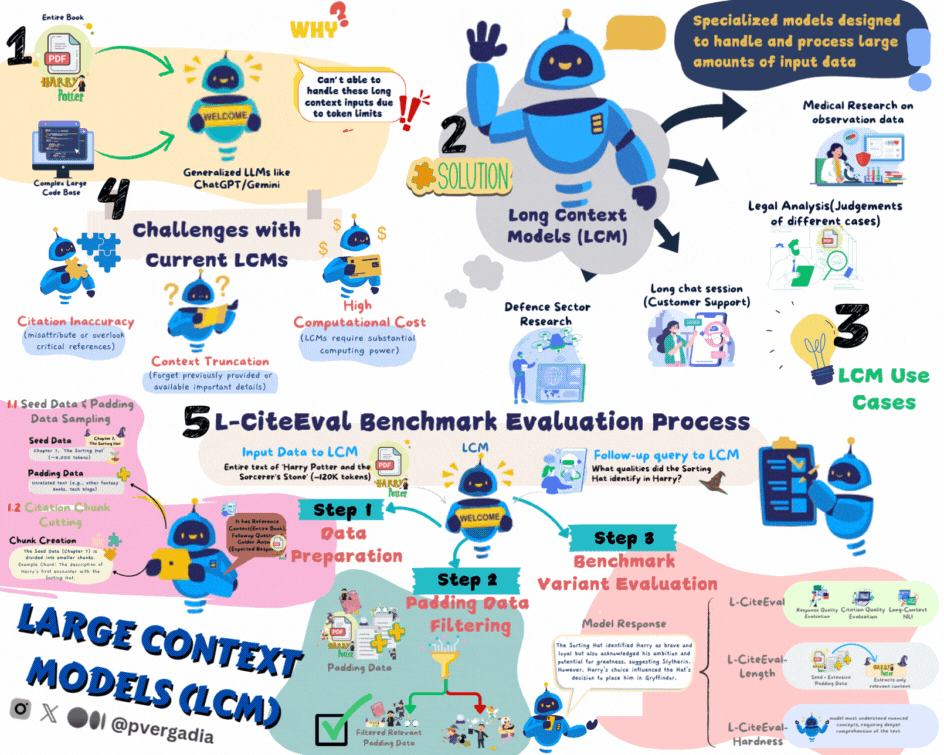
LCMs are the latest solution to a longstanding problem in AI, handling and understanding lengthy text inputs effectively. Traditionally, models like GPT and others excel with shorter passages but struggle as input length increases. LCMs help!

Large Context Models (LCMs) were developed to bridge the critical gap in processing lengthy information, enabling deeper and more comprehensive engagement with extensive content across diverse fields.
Legal Analysis: Where contracts and laws span thousands of pages.
Medical Research: Understanding literature reviews and systematic reviews.
Customer Support: Managing extensive conversations and logs.
Defence Sector: In Defence, it can enhance real-time decision-making, intelligence analysis, and autonomous systems by processing extensive data streams with high contextual awareness.
As these models continue to revolutionize how we process and understand long-form content, they have become a central focus of contemporary AI research, promising to open new possibilities in data analysis and comprehension across industries.
Challenges with the Current Approach for LCMs
While LCMs are promising, they aren't without their challenges.

Key problems include:
Context Truncation: As the context length increases, many models begin to forget or ignore earlier parts of the input. This means that when tasked with understanding a book-length document, they might miss crucial details mentioned at the beginning.
Citation Inaccuracy: One of the biggest challenges is maintaining accurate references to source materials. LCMs may misattribute or overlook critical references, which can be problematic in fields where precision is essential.
Computational Cost: LCMs require substantial computing power, making them harder to scale for real-time applications or in environments with limited resources.
Key Findings
Current research in Large Context Models includes benchmarks like LongBench, Longcite, and Ruler. L-CiteEval introduces a new standardized benchmark for evaluating LCMs, designed to address existing challenges in long-context model assessment. These limitations include:
Limited focus on citation quality: Many benchmarks primarily evaluate LLM performance based on the correctness of generated answers, neglecting the importance of supporting citations.
Inconsistent evaluation methods: Real-world tasks vary widely in format and evaluation methods, leading to inconsistencies in evaluations across different works.
Influence of intrinsic knowledge: Existing evaluations can be influenced by the intrinsic knowledge of LLMs, making it difficult to assess their ability to rely solely on the provided context.
L-CiteEval addresses these issues by:
Prioritizing citation quality: It evaluates both the correctness of generated statements and the quality of supporting citations.
Comprehensive task coverage: It includes a diverse range of tasks, from single-document QA to synthetic tasks, to ensure a thorough evaluation.
Controlled evaluation: It offers L-CiteEval-Length and L-CiteEval-Hardness variants to isolate the impact of context length and task difficulty.
L-CiteEval Benchmark Evaluation Process
The L-CiteEval benchmark evaluation process involves a lot of steps so to make it a bit easier, let’s use "Harry Potter and the Sorcerer's Stone" (One of the most popular book in the world) as input to evaluate a Long-Context Model (LCM) through the L-CiteEval benchmark.

Input Prompt:
Entire text of Harry Potter and the Sorcerer’s Stone (about 76,944 words or ~120K tokens).
Follow Up Query prompt to LCM:
What qualities did the Sorting Hat identify in Harry?
Step 1: Data Preparation

Seed Data & Padding Data Sampling:
Seed Data:
A segment of the book, such as Chapter 7, The Sorting Hat (~4,000 tokens).Padding Data:
Additional unrelated data, such as text from another fantasy book or unrelated topics like tech blogs, is added to test the model's ability to focus on relevant content.
Citation Chunk Cutting: The chapter is divided into chunks:
Example Chunk: The description of Harry's first encounter with the Sorting Hat as we asked a followup question related to sorting hat’s decision of deciding where Harry will go based on his quality.
Step 2: Padding Data Filtering
Any irrelevant padding data closely related to the question but outside the book's content is filtered out to avoid influencing the results.

Step 3: Benchmark Variant Evaluation
This step will provide you an end-to-end insights related to efficiency of your LCM. Reference to the same Harry potter example, suppose Model has responded with the below context on the follow-up question - What qualities did the Sorting Hat identify in Harry?
"The Sorting Hat identified Harry as brave and loyal but also acknowledged his ambition and potential for greatness, suggesting Slytherin. However, Harry's choice influenced the Hat's decision to place him in Gryffindor."

In the L-CiteEval Benchmark, we evaluate model in three parameters
L-CiteEval:
It provides holistic evaluation of response quality and citation accuracy. the model earns a high score if it correctly captures the Sorting Hat’s reasoning, cites appropriate sections, and omits irrelevant context.
Response Quality Evaluation:
Precision: Does the response mention correct attributes like bravery and ambition?
Recall: Does the model miss any qualities discussed in the book?
ROUGE-L: Measures how well the model's summary matches reference text from the chapter.
Citation Quality Evaluation:
Citation Recall: Checks if the response refers to the correct scene (Sorting Hat’s dialogue).
Citation Precision: Assesses if all cited text aligns with the relevant book section.
Citation F1 Score: Balances recall and precision.
Long-Context NLI:
The model is tasked to justify: "Does the Sorting Hat's decision align with its stated reasoning?"
An NLI model verifies if the cited text (Sorting Hat dialogue) supports the conclusion (Harry in Gryffindor due to bravery and loyalty).
L-CiteEval-Length:
Test: Does the model perform consistently when the book is paired with extensive padding data (e.g., unrelated fantasy content)?
Outcome: A robust model focuses solely on Harry Potter despite distractions.
L-CiteEval-Hardness:
Test: A more complex query like "Explain the moral implications of the Sorting Hat’s decision-making process."
Outcome: The model must understand nuanced concepts, requiring deeper comprehension of the text.
Tasks and Metrics
The following tasks and metrics are used in the evaluation process to ensure the model undergoes a comprehensive evaluation.
Task Diversity:
Question Answering:
"What did Dumbledore say about the Mirror of Erised?"Model must locate and summarize Dumbledore’s explanation.
Summarization:
"Summarize Harry’s first encounter with Voldemort in the book."ROUGE and BLEU evaluate summary quality.
Text Generation:
"Continue the Sorting Hat's monologue in a similar tone and style."Evaluated for coherence and style consistency.
Evaluation Metrics:
ROUGE: Measures overlap in summaries.
BLEU: Assesses n-gram precision for tasks like rephrasing or extending text.
Custom Metrics: Ensure citations (e.g., Sorting Hat’s reasoning) are accurate and relevant.
That’s all! Here, we’ve completed our LCM’s evaluation process using the L-CiteEval benchmark. This comprehensive process has gives us insights into how well long-context models handle various tasks, maintain citation accuracy, and leverage extended context to generate meaningful, relevant responses. By following these steps, we can effectively gauge the model's performance and identify areas for improvement.
Key insights from the paper:
L-CiteEval compared a wide range of LCMs, including both open-source and closed-source models. The benchmark evaluated these models on tasks such as question answering, summarization, and text generation.
Open-Source vs. Closed-Source Models: While open-source models demonstrated strong overall performance, they tended to be less accurate in citing sources compared to closed-source models. This suggests that closed-source models may have access to additional data or training techniques that improve their ability to leverage context.
Impact of Model Size: Larger models generally outperformed smaller models on L-CiteEval. This indicates that increasing model size can lead to improved performance, especially for tasks that require deep understanding of the context.
Effect of Training Data: The quality and quantity of training data can significantly impact a model's performance. LCMs trained on large, diverse datasets tend to exhibit better results on L-CiteEval.
Attention Mechanisms: The choice of attention mechanism can influence a model's ability to focus on relevant parts of the input. Some attention mechanisms, such as transformers, have been shown to be particularly effective for long-context tasks.
Retrieval-Augmented Generation (RAG): RAG techniques, which involve retrieving relevant information from a knowledge base, can improve the faithfulness of LCMs to the given context. However, they may introduce additional computational overhead, if you want to explore more about RAG, this blog can be a good start point for you
Why Do LCMs Matter?
This research matters because LCMs are poised to revolutionize how we interact with large volumes of information. For businesses, academia, and industries relying on lengthy documentation, LCMs can automate and speed up processes that were once manual and time-consuming. Improved citation accuracy and context handling mean more reliable AI, reducing the need for human verification. This can greatly impact:
Healthcare: Automating the summarization of patient records.
Research: Synthesizing findings across thousands of studies.
Legal: Streamlining the analysis of contracts and case law.
Conclusion: Our Thoughts
The L-CiteEval benchmark represents a critical step forward in understanding the true potential of long-context models. It highlights current limitations in how models handle extended inputs while offering a roadmap for future improvements. Closed-source models may currently have an edge, but the improvements seen with techniques like RAG indicate that open-source models have the potential to catch up.
As we continue to push the boundaries of what LCMs can do, the future looks promising for AI's ability to navigate and synthesize long-form content. This means more accurate, reliable, and context-aware AI systems that can be applied across a multitude of domains.
Additional Resources
Excited to explore more? Here is an amazing github repo by Huanxuan Liao about the Long-context language model, which includes different research works, hands-on demonstrations etc.