
How to use Gemma models in Google Cloud?
Google just announced Gemma, a new family of lightweight and open-source AI models aimed specifically at developers and researchers like you. Here's the lowdown:
Understanding Gemma
Gemma is a collection of lightweight AI models available in two sizes: 2B and 7B parameters.
They're built on the same research and technology as Google's powerful Gemini models, but scaled down for efficiency and accessibility.
Open-source means you can use them for free, modify them, and contribute to their development.
You can use Gemma models in Colab and Kaggle notebooks and even on your laptop or workstation.
You can also deploy Gemma in Google Cloud on Vertex AI and Google Kubernetes Engine.
How to use Gemma in Google Cloud?
Step 1: You can access Gemma foundational model in Vertex AI Model Garden. Foundational models are pre-trained models that can be further tuned for specific tasks. You an also access other models from here including Google’s Gemini Pro, Gemini Ultra, other open source and partner models such as Claude and Llama.

Access Gemma Foundation models from Vertex AI Model Garden
Step 2: Once you select the foundation model you can see the details about the model, view code, open a Colab notebook, test and deploy it. You can put a text prompt in “Try out Gemma“ section.

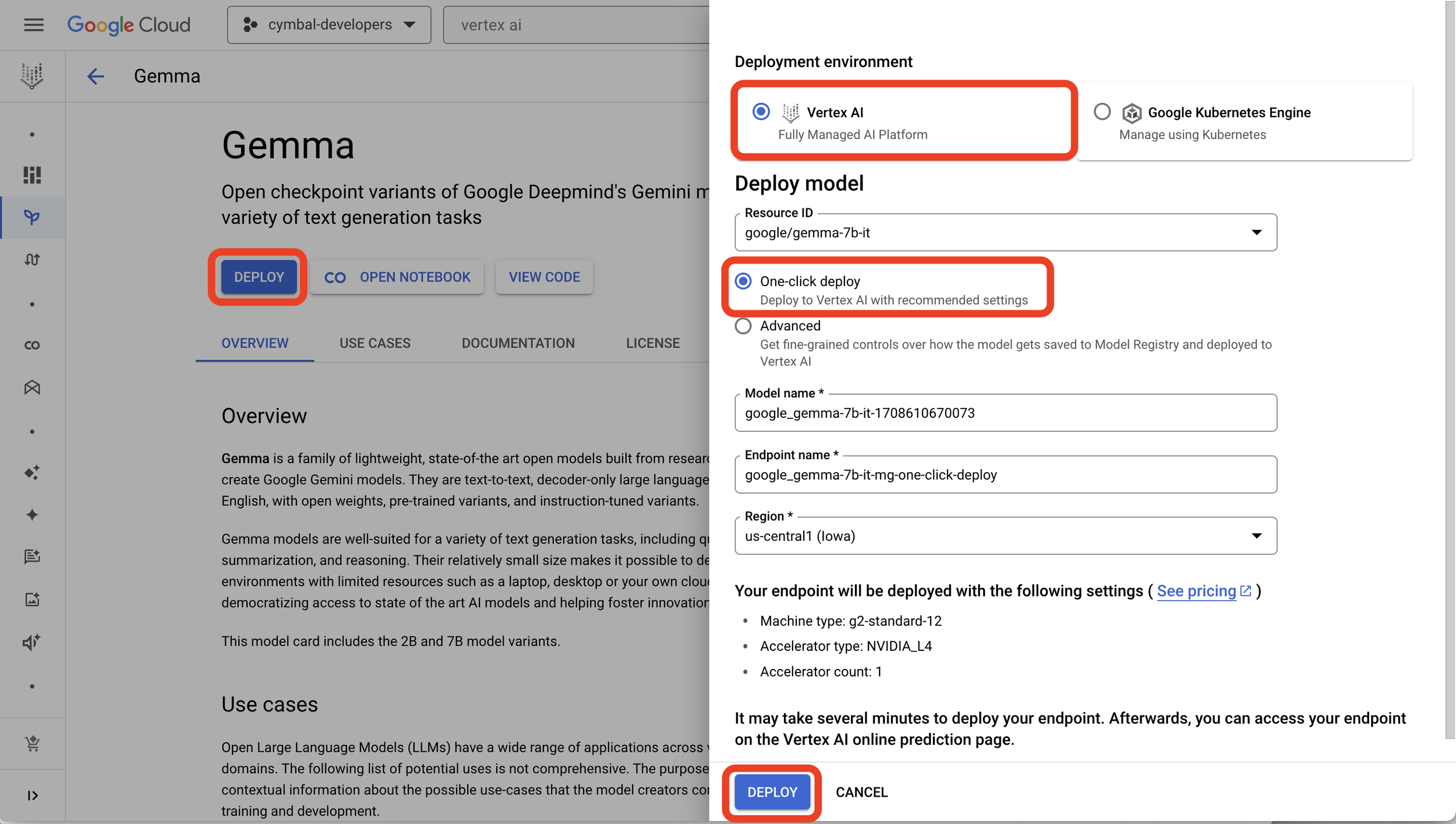
Step 3: You can deploy Gemma in your own project in Google Cloud using Vertex AI or Google Kubernetes Engine. I selected Vertex AI here and you can select one-click deploy to straightaway deploy it in your cloud environment. It takes a few mins to see the deployed endpoint.
Step 4: Once the endpoint is deployed you can see it in “Online Predictions” and click on “Sample Request” to see how to frame your request to call the endpoint.
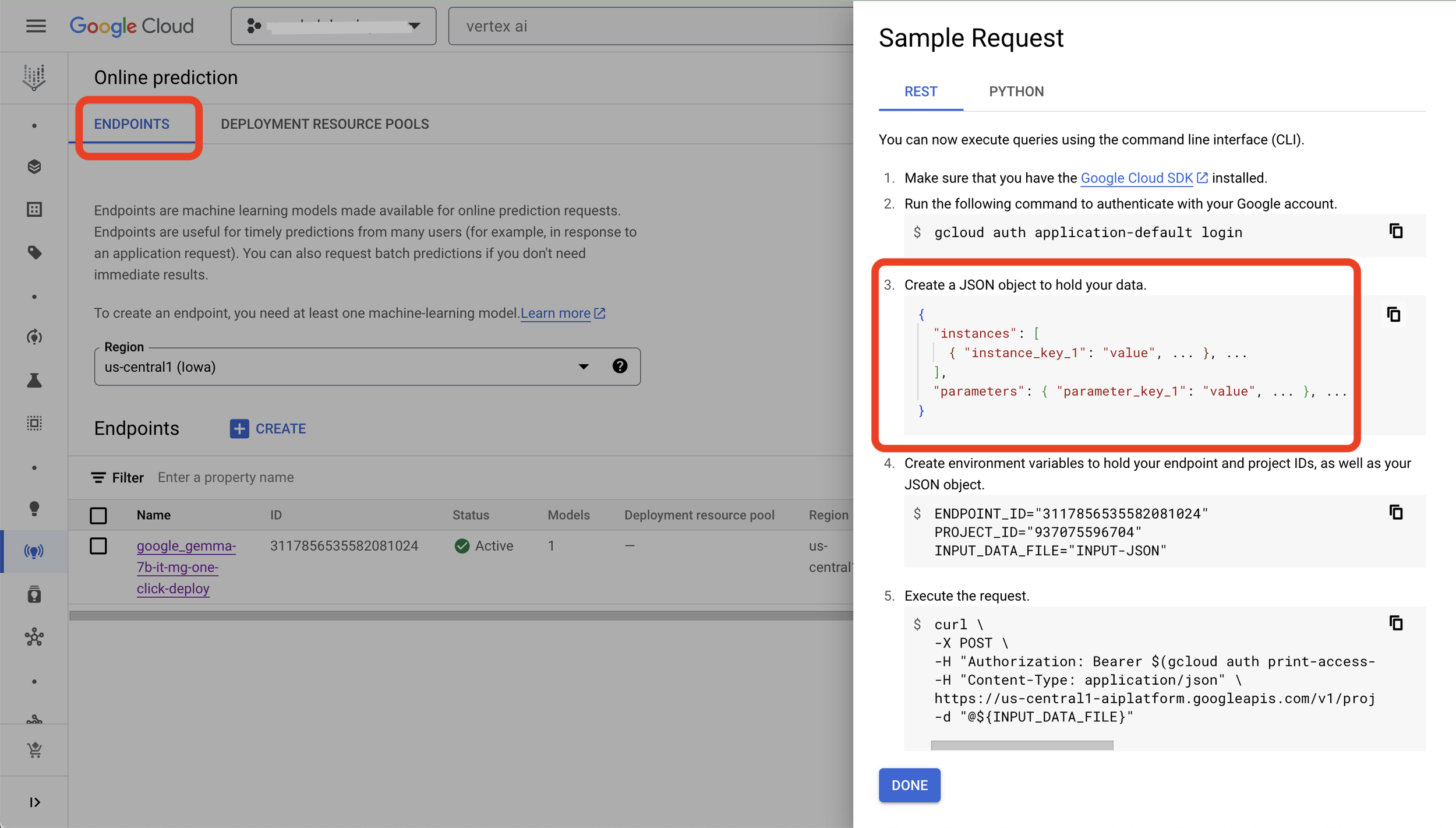
This is my first and very short version of how to get started with Gemma on Google Cloud. I am excited to hear from you how you use it!
You can also read more details in announcement blog: https://blog.google/technology/developers/gemma-open-models/